Analytics Vidhya là 1 trang chuyên về phân tích dữ liệu (data analytics) của Ấn Độ. Lĩnh vực phân tích dữ liệu là 1 lĩnh vực mới, tuy nhiên đang được đón nhận tích cực tại Mỹ, Ấn Độ và nhiều quốc gia khác trên thế giới. Từ tháng 6 trở lại đây, Analytics Vidhya đều đặn tổ chức các cuộc thi data hackathon hàng tháng, thu hút 1 số lượng không nhỏ các ứng viên. Tháng 8 - 2015, tôi có tham gia và đạt hạng 7 chung cuộc trên tổng số 273 thí sinh tham dự cuộc thi Online Hackathon - Find the next Brain Wong!. Bài viết này nói về cách tiếp cận và giải quyết vấn đề trong cuộc thi đấy của tôi.
1, Giới thiệu yêu cầu
Yêu cầu của cuộc thi lần này là tính toán ra giá trị đầu tư của các dự án trong các trường học ở Mỹ, khi biết các thông tin đầu vào của dự án. Chúng ta sẽ đưa ra dự đoán dự án nào sẽ được đầu tư, và đầu tư bao nhiêu?
Các biến được sử dụng ở training set và test set như sau:
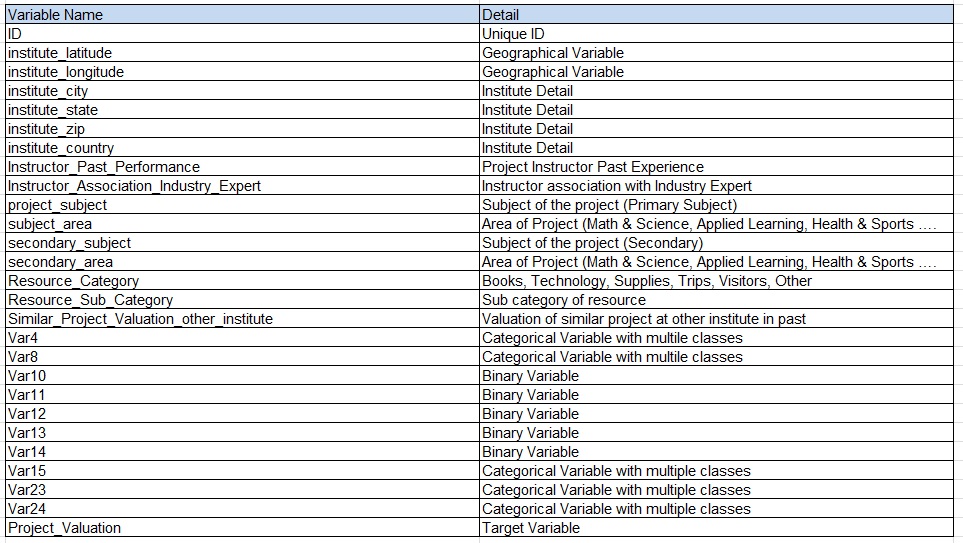
Cuộc thi có kiểm tra đáp án với 30% test set, và lần đánh giá cuối cùng là đáh giá 100% test set. Phương pháp đo lường sai số được sử dụng là RMSE.
Bạn có thể download training set và test set ở đây.
2, Bắt đầu
Việc ngắm nghía qua dữ liệu, cũng như phát hiện các đặc điểm của dữ liệu rât quan trọng để đưa ra các phán đoán và hướng đi giải quyết vấn đề (bạn có thể tham khảo thêm cách tiếp cận của những người tham dự khác trong cuộc thi ở đây). Khi tìm hiểu qua các biến, có 1 số biến với các đặc điểm khác biệt như sau:
- 2 biến institute_latitude và institute_longitude lần lượt là vĩ độ và kinh độ của từng project. 2 biến này cần kết hợp với nhau thì mới đưa ra được thông tin chính xác về vị trí của dự án, chỉ 1 biến latitude hay longitude đều không mang ý nghĩa quá lớn về vị trí địa lý.
- biến institute_country không phải là quốc gia của các project mà là county (địa hạt) của project (ở đây dữ liệu bị sai chính tả, tuy nhiên điều này không quá quan trọng)
- var10, var11, var12, var13, var14 đều là các biến nhị phân nên sẽ không có thay đổi hay đánh giá được gì :))
- sau khi tìm hiểu, tôi nhận ra được Var8 là về loại khu vực của các institudes, được chia ra làm 4 loại chính là: urban, suburban, rural, other.
Từ 1 vài đặc điểm ban đầu này, ta có thể đưa ra các giả định, sau đó tiến hành kiểm tra và làm việc dưa vào các giả định ấy.
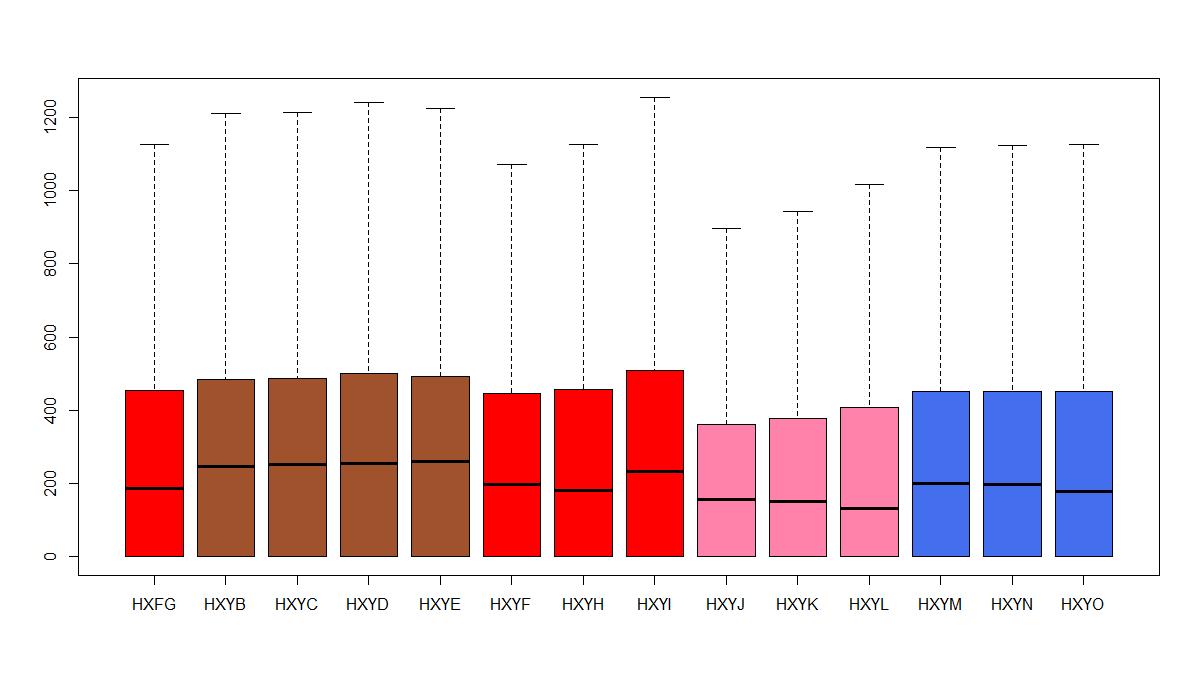
- Var8 (loại khu vực): kết quả được lựa chọn đầu tư có thể được chia theo 4 loại khu vực
Chúng ta có thể dựng mô hình mức độ đầu tư dựa vào các loại khu vực để kiểm tra giả định là đúng hay sai.
boxplot(training_set$Project_Valuation ~ training_set$Var8, outline=F, col = c("red","sienna","sienna","sienna","sienna","red","red","red",
"palevioletred1","palevioletred1","palevioletred1","royalblue2","royalblue2",
"royalblue2"))
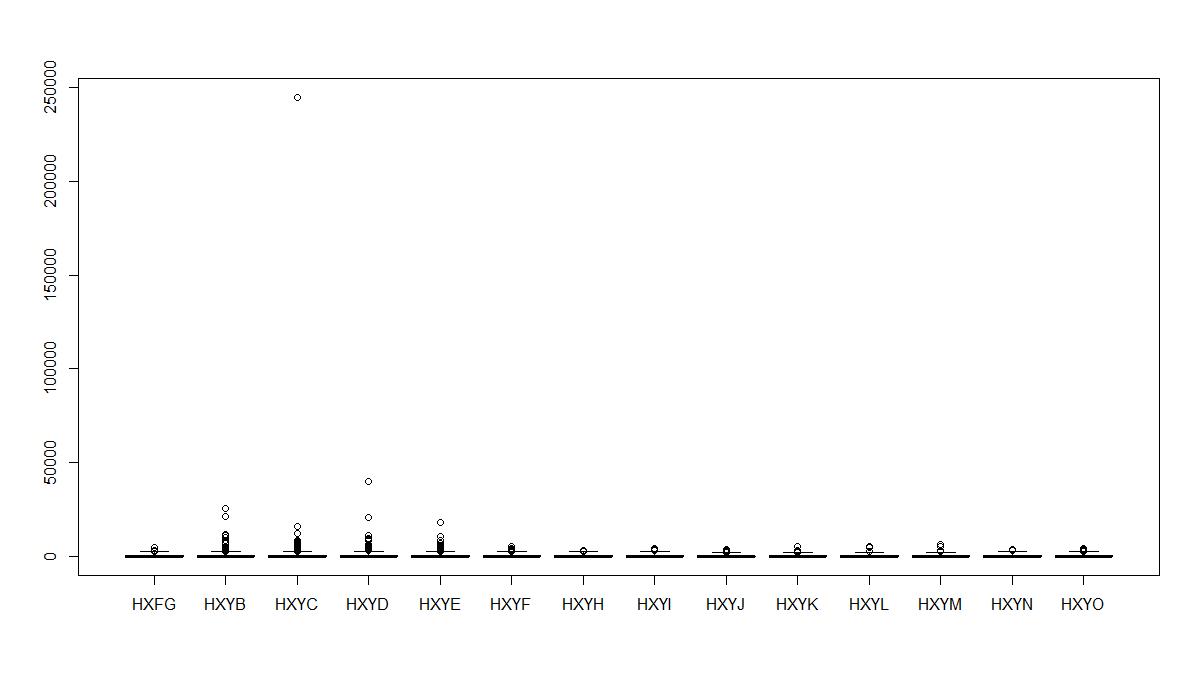
Khi cho phép hiển thị các outliers, bạn có thể nhận thấy rõ ràng hơn:
boxplot(training_set$Project_Valuation ~ training_set$Var8, outline=T, col = c("red","sienna","sienna","sienna","sienna","red","red","red",
"palevioletred1","palevioletred1","palevioletred1","royalblue2","royalblue2",
"royalblue2"))
Như vậy, bạn có thể tạo ra 1 biến mới chỉ bao gồm 4 loại khu vực sau khi đã phân loại.
levels(training_convert_set$Var8)[levels(training_convert_set$Var8) == 1||6||7||8] = 2
levels(training_convert_set$Var8)[levels(training_convert_set$Var8) == 2||3||4||5] = 1
levels(training_convert_set$Var8)[levels(training_convert_set$Var8) == 9||10||11] = 3
levels(training_convert_set$Var8)[levels(training_convert_set$Var8) == 12||13||14] = 4
- yếu tố vị trí địa lý có liên quan đáng kể tới lượng đầu tư của dự án.
Từ giả định này, tôi quyết định kết hợp 2 biến longitude và latitude lại thành 1 biến mới biểu thị tọa độ địa lý của project. tôi quyết định lựa chọn biến mới theo công thức: geo = (institute_latitude)^3 + (institute_longitude)^2. Tôi lựa chọn công thức này để đảm bảo tọa độ địa lý của project sẽ tỷ lệ thuận với giá trị biến geo.
training_convert_set$geo = (training_set$institute_latitude)^3 + (training_set$institute_longitude)^2
Khi đã có 2 biến mới geo và Var8 (được chỉnh sửa), tôi quyết định 2 biến này và biến city sẽ thay thế toàn bộ các biến mang thông tin về địa lý.
Ban đầu, tôi chạy thử với mô hình glm, kết quả đạt được đủ để tôi lọt vào top 20, nhưng vẫn chưa đủ tốt. Sau khi có 1 số điều chỉnh, tôi quyết định chuyển sang mô hình random forest. Khi chạy mô hình random forest với ntree = 300 và nodesize thay đổi từ 20 tới 100, tôi thấy mô hình hoạt động tốt khi nodesize dao động ở giá trị 70. Tôi cố gắng kết hợp 2 mô hình lại nwhng không thu được kết quả như ý, vì vậy kết quả cuối cùng chỉ bao gồm mô hình random forest.
2019 Update:Code này mình up lên github nhưng hồi đó ngu dại, up kiểu gì mà không có code =)) thôi coi nó đi vào dĩ vãng vậy. Bài này mình viết gần 4 năm rồi, hồi đó vừa học nên cũng chưa biết gì, giờ đọc lại cũng thấy hơi buồn cười nhưng cũng là tâm huyết 1 thời của mình, nên dẫu ngây ngô chút nhưng cũng rất đáng quý hehe.
3, Kết luận
Ở public leaderboard, tôi chỉ đạt được thứ hạng 12, và có 1 khoảng cách không nhỏ với top 10. Tuy nhiên, ở private leaderboard, tôi đã cải thiện thứ hạng và leo lên được hạng 7, với khoảng cách sít sao với hạng 6 và hạng 5 (nếu như tôi có thể cải thiện mtry, tôi nghĩ tôi có thể đạt được hạng 5). Tôi không cho rằng mô hình của tôi không ổn định, mà bởi vì 1 số người đã quá cố gắng điều chỉnh mô hình cho hợp với puclic leaderboard dẫn tới việc overfitting và kết quả chung cuộc suy giảm.
Tháng 9, Analytics Vidhya có tổ chức tiếp tục 1 cuộc thi hackathon với hơn 500 thí sinh tham dự (ngang với vài cuộc thi cỡ nhỏ của Kaggle, và vượt xa các trang khác). Rất tiếc, lần này tôi không sắp xếp được thời gian để tham gia. Có lẽ lần tới, tôi sẽ tham gia vào cuộc thi tháng 10 của Analytics Vidhya nếu nó vẫn được diễn ra như thường lệ.
