I’ve been a Cursor user for nearly a year and have been quite satisfied with it overall. However, after recently hitting my quota limit, I decided to explore an alternative tool - Cline. While checking through OpenRouter, I noticed that Roo, a fork of Cline, had comparable token usage, so I switched gears and gave Roo a try.
In short: Roo is a developer tool that lets you code alongside AI, similar to Cursor. The key difference is that with Roo, you connect your own preferred LLM APIs directly, giving you the flexibility to customize prompts and settings at will.
Here are some quick observations from my first morning spent using Roo:
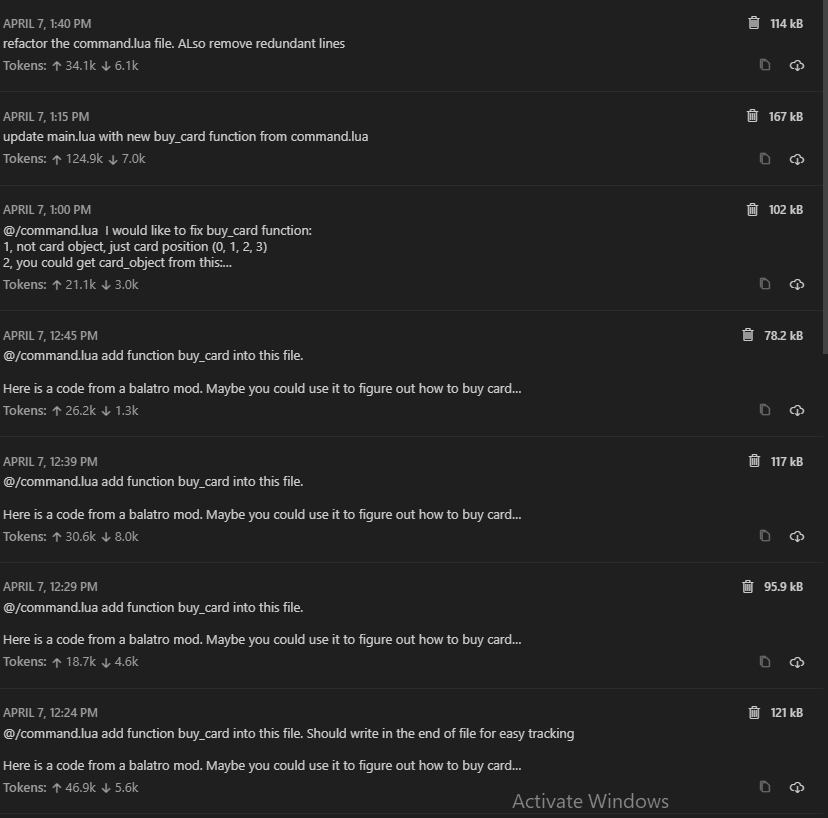
My usage for an hour
-
Great first impressions:
Roo is a joy to use. Given the freedom and enough resources (tokens), it generally returns quite impressive results. So far, I’ve only tried its “Task” mode without delving into the other modes and advanced capabilities. Onboarding was notably quicker and simpler than I expected.
-
Control:
Using Roo gives you significantly more control. Basically, you’re less likely to run into the infamous “vibe coding” issue, where you have a ton of fun coding with AI but later can’t even understand your own code anymore =))). Those who often complain about vibe coding randomness might appreciate Roo a bit more.
-
Token Hungry:
Roo consumes a large number of tokens. The attached image illustrates Roo’s token usage after I carefully optimized—it typically requires two-to-three times more in unoptimized scenarios.
-
Costs:
With careful and moderate usage (Gemini Pro 2.5, as a best-in-class coding model), costs average around 1 USD/hour. With intensive usage, it’s pretty normal to hit around 5 USD/hour.
-
Context Overload:
It feels like Roo just loads your entire file context directly to the LLM (though I need further tests to confirm if this is always the case). It might work okay for small-to-medium repositories, but it becomes troublesome for a large and complex codebase. Cursor has indexing already integrated to alleviate this issue. You could handle this context-sensitive issue yourself with tools like MCP, although it’s still a bit cumbersome to set up.
-
How Does Cursor Control Costs?
Considering the high token consumption and associated costs, along with built-in Cursor features (such as indexing, Cursor tabs, etc.), I can’t help but wonder how exactly Cursor maintains profitability at scale. Perhaps they’re cropping the context passed to models, or they’re occasionally using watered-down models (we can only guess). This might explain why Cursor sometimes seemingly underperforms out of nowhere, prompting me to switch over to GPT-4 or Claude directly (which then typically performs much better, even with zero context provided).
-
Smart Routing is Crucial:
Seeing these costs clearly highlights to me how important intelligent, multi-model routing is. If we split tasks strategically, offloading simpler tasks to lighter but sufficiently capable models (like Gemini 2.0 Flash), reducing expenses to 1/4 or 1/5 of current rates is completely achievable. This smart routing concept is something I’ve become increasingly interested in recently. There’s already work going on in this space with solutions like Requesty or noDiamond—although I haven’t personally verified their effectiveness yet. Cursor recently also introduced auto-selection of LLMs (likely for cost-cutting), but at least in my case, I still prefer using robust and expensive models.
I’m aware of other considerations that often motivate people’s choices, such as data privacy, open-source approach, or running models locally - but those particular factors don’t play a significant role for me personally.
