Hợ hợ tuần rồi chưa viết được bài nào. Bài này là viết bù cho tuần trước đây. Tuy nhiên bài này quá dài nên coi như 2 bài cũng ok :))
Bài viết hôm nay là Deep Reinforcement Learning Doesn’t Work Yet. Đây là 1 bài viết của 1 Googler chuyên về RL trong robotic, nói về khả năng ứng dụng RL trong thực tế và những bài toán mà RL có thể giải quyết, cũng như những vấn đề điểm yếu hiện này của RL. Ngoài ra, cảm giác của mình là nếu ai có thể giải quyết được vấn đề transfer learning trong RL, người đó sẽ đi đầu xu thế.
Dưới đây là nội dung bài viết qua ý hiểu của mình.
Intro
Tác giả nói rằng, phần lớn những vấn đề bạn gặp hiện nay, RL không giải quyết được.

Khẳng định của tác giả
Cụ thể hơn, các mục dưới đây nói về những TH thất bại của Deep
Quá không hiệu quả
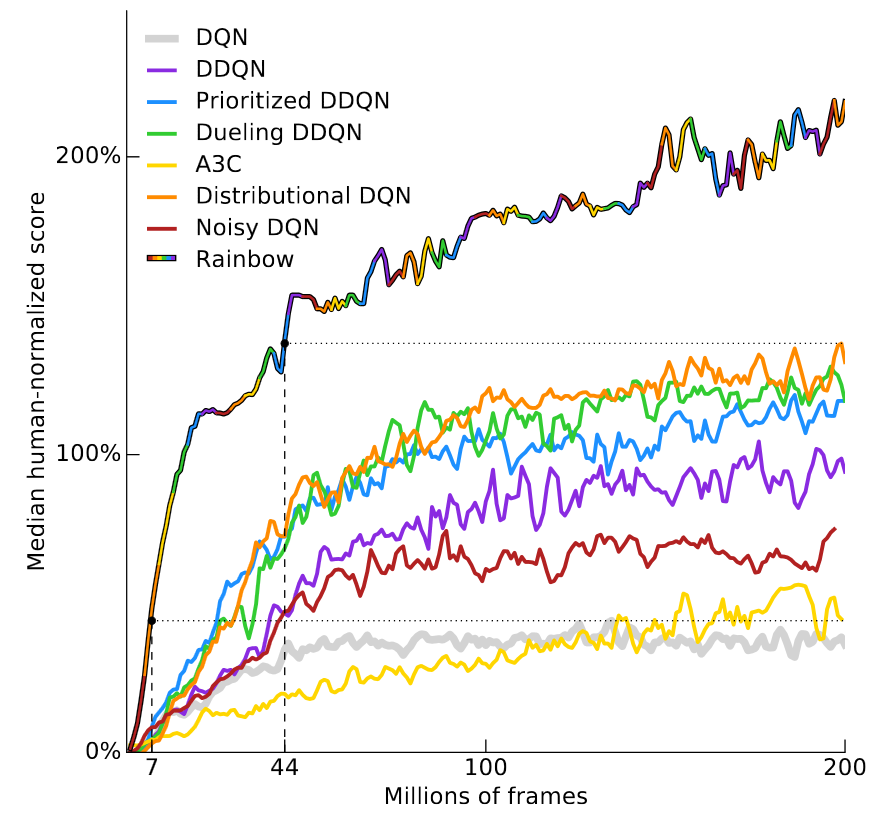
Mức độ training khủng khiếp khi chơi các game Atari
Cho tới năm 2017, vẫn cần tới 18 triệu frames tương đương với 83 giờ chơi để RL có thể đạt ngang trình độ bình thưởng của con người. Đây là chưa tính thời gian training, chỉ tính số frames được nhận làm input. Các ví dụ của Open AI, sử dụng hàng trăm, hàng ngàn GPU là những ví dụ khủng khiếp kiểu vậy.
Nếu chỉ chơi game Atari, ta có hàng trăm phương pháp đơn giản hơn nhiều.
Nếu chỉ care về performance, RL không phải ý kiến hay
Nó là tiếp nối ý trên. Có nhiều bài toán mà ta có domain knowledge, RL rất sida để dùng. Hãy nhớ Boston robotic hoàn toàn ko dùng RL!!!
Reward function là 1 vấn đề quá khó giải quyết
Tại sao chúng ta thường dùng game trong RL? Bởi vì game có hệ thống rule và reward rất chi tiết cụ thể.
Nhưng ngoài đời thì không. Ta thậm chí còn đánh nhau suốt ngày chỉ vì xem reward đời người nên là gì.
Và dù cho có đúng reward, thì việc ra policy maximize được reward lại chưa hẳn đã là thứ ta cần.
Vấn đề local optima và tương tự cực kỳ cực kỳ nghiêm trọng trong RL
Nó bổ sung cho ý ở trên.
Vậy RL có ý nghĩa không?
Có, bởi có những bài toán, hiện tại chỉ RL mới giải quyết được.
Vd như Open AI Dota.
Vậy khi nào áp dụng RL?
- easy trong việc tạo ra không giới hạn data. (game là 1 ví dụ tuyệt vời)
- có khả năng self-play.
- clean-way to define reward
Lời cuối
Nếu như có transfer learning, mình tin RL sẽ có những bước tiến vũ bão.
Còn nhiều hướng tác giả viết mình thấy bình thường.
Cá nhân mình nghĩ RL có 1 hướng rất sáng ở việc làm bot cho game. Yeah, đó là 1 hướng cực kỳ tuyệt vời và tiềm năng.
